Replace ZFS RAIDZ1 disk
I recently had the displeasure of dealing with a series of failed disks in my newly created ZFS based NAS. I had cobbled together roughly 12TB of disk space and jammed them into an old PC, stretching the limits of the platform when I decided to go with ZFS. I broke all of the rules, underpowered, single core PC, only a handful of GIG of non-ECC RAM, etc. I’m sure storage guys are having a coronary after reading that, but it works for me and has minimal issues since I just relatively redundant need bulk storage and it doesn’t need to be fast (the ethernet connection is only 100M). Machine stats are as such: AMD Sempron(tm) Processor 2800+ 2G NON-ECC memory The following disks:
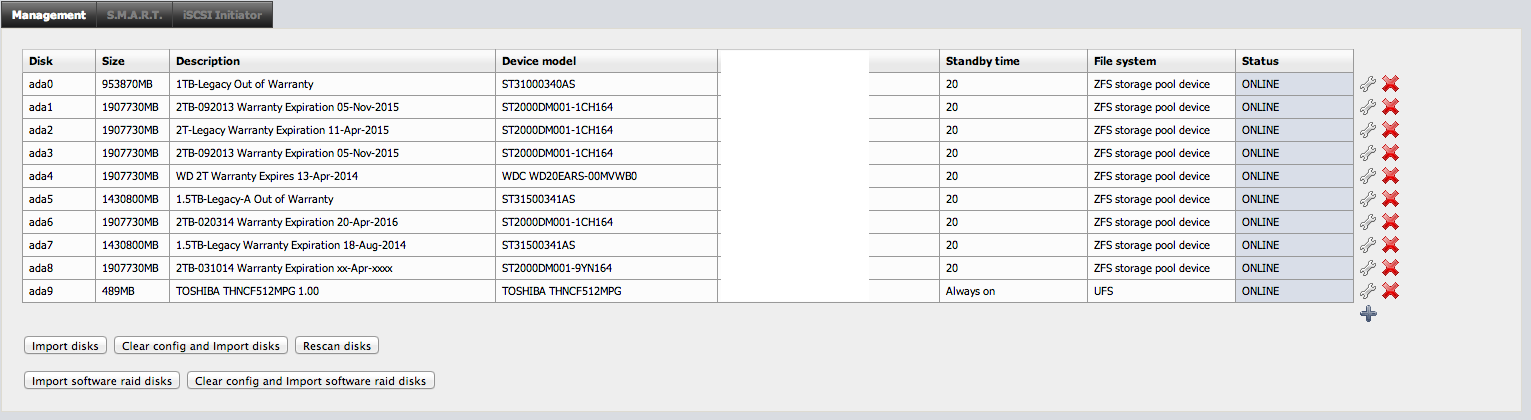
The NAS was a long standing device on my network. I’ve been using NAS4FREE for quite some time with fantastic results. The disks are simply desktop drives, nothing fancy. When I rebuilt it all using ZFS I found that I had not done 2 things. I had not documented the warranty status of the devices and I had not enabled SMART monitoring. I know, amateur hour at its finest; I’m OK with it, it’s just for home use and I have offsite storage for anything super important. *As an aside, if you’re looking to build a NAS I would both recommend NAS4FREE as well as doing something as simple as documenting the warranty information of each disk in the description field. So, when I enabled SMART monitoring and email reporting. I found that several of my disks were failing their end-to-end tests when this started showing up in my inbox:
The following warning/error was logged by the smartd daemon:
Device: /dev/ada1, Failed SMART usage Attribute: 184 End-to-End_Error.
Device info:
ST2000DM001-1CH164, S/N:xxxxxxxx, WWN:5-000c50-08147e2a4, FW:CC26, 2.00 TB
Bad news. However, with ZFS it is supposed to be fantastically easy to do disk replacements. I had chosen RAIDZ1 for both volumes, so they could each supposedly sustain a single disk failure. There are a lot of online references for zfs. I used this page as a starting point for replacing my disk. I dropped to the shell on the NAS and did the following to identify the right disk to remove:
nas:~# camcontrol devlist
<ST31000340AS SD15> at scbus0 target 0 lun 0 (ada0,pass0)
<ST2000DM001-1CH164 CC26> at scbus1 target 0 lun 0 (ada1,pass1)
<ST2000DM001-1CH164 CC24> at scbus2 target 0 lun 0 (ada2,pass2)
<ST2000DM001-1CH164 CC26> at scbus3 target 0 lun 0 (ada3,pass3)
<WDC WD20EARS-00MVWB0 51.0AB51> at scbus4 target 0 lun 0 (ada4,pass4)
<ST31500341AS CC1H> at scbus5 target 0 lun 0 (ada5,pass5)
<ST2000DM001-1CH164 CC29> at scbus6 target 0 lun 0 (ada6,pass6)
<ST31500341AS CC1H> at scbus7 target 0 lun 0 (ada7,pass7)
<ST2000DM001-9YN164 CC82> at scbus8 target 0 lun 0 (ada8,pass8)
<TOSHIBA THNCF512MPG 1.00> at scbus11 target 0 lun 0 (ada9,pass9)
ada8 needs replaced. The volume it exists in is zfs0. The formula used is “zpool
zpool offline zfs0 ada8
None of my stuff is hot swap, so I have to shut down the box.
shutdown -h now
Yank out the old disk and install the new one.
zpool replace zfs0 ada8
zpool online zfs0 ada8
After that you’ll see the disk getting resilvered, which will take a while.
nas:~# zpool status zfs0
pool: zfs0
state: DEGRADED
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scan: resilver in progress since Mon Mar 10 13:39:36 2014
105G scanned out of 3.37T at 75.4M/s, 12h36m to go
17.5G resilvered, 3.04% done
config:
NAME STATE READ WRITE CKSUM
zfs0 DEGRADED 0 0 0
raidz1-0 DEGRADED 0 0 0
ada1 ONLINE 0 0 0
ada2 ONLINE 0 0 0
ada3 ONLINE 0 0 0
ada4 ONLINE 0 0 0
ada6 ONLINE 0 0 0
replacing-5 OFFLINE 0 0 0
6070465578770542405 OFFLINE 0 0 0 was /dev/ada8/old
ada8 ONLINE 0 0 0 (resilvering)
errors: No known data errors
After the resilvering process you should have a repaired volume.